Для того, чтобы понять, что такое "многобайтные символы" необходимо прежде всего определиться с термином "байт".
Принято считать, что байт - это порция информации, состоящая из восьми бит. Но существует и намного более точное определение - октет. То есть, в принципе, мы можем группировать информацию порциями любого другого размера. Например, в телеграфии до сих пор применяются пяти-битные порции информации (байты).
Максимальное количество разных значений, которые мы можем закодировать в восьми-битном байте - 256=28 (от 0 до 255) а в пяти-битном - 32=25.
Теперь предположим, что нам необходимо закодировать некую информацию, например символы алфавита (буквы) в двоичных числах. Подробно об операциях кодирования см. Языки, символы и кодировки.
Рассмотрим, например, тот же телеграфный код. Оказывается, закодировать 26 английских букв и 10 цифр в 32 разные комбинации не удается. Для этого применяют специальный символ : переключение регистра. А если сюда добавить еще и русские буквы, регистров становится целых три : ЛАТ, РУС, ЦИФ. Именно так образуется Международный Телеграфный трех-регистровый Код MTK-2, принятый в CCCP в 1963 году.
Если кто-нибудь еще помнит такую технику, как ДВК (Диалоговый Вычислительный Комплекс), то там применялся КОИ-7 (Код Обмена Информацией, 7-ми битный). Однако этот код содержал все символы ASCII, (маленькие и большие латинские буквы) и все символы кириллицы, также маленькие и большие. Что в результате давало более чем 128=27 кодовых позиций. А для переключения между латинской КОИ-7Н0 (набор N0) и русской КОИ7-Н1 (набор N1) половинами использовались коды SO (Shift Out, 014) и SI (Shift In, 015).
Например для того, чтобы отобразить на терминале фразу : "Мир, Peace" необходимо послать следующие символы :
| SO | 0155 | 0111 | 0122 | 054 | 040 | SI | 0120 | 0145 | 0141 | 0143 | 0145 |
После переключения в другую кодовую страницу (русский регистр) его состояние сохраняется до переключения в латинский регистр.
![]() Таким
образом мы приходим к важнейшему понятию в
технологии многобайтных символов : Shift
State (можно перевести как Регистр
или Состояние Регистра). На самом
деле, таких состояний (регистров) может быть
несколько, они могут быть
взаимоисключающими, или же действовать
одновременно и независимо.
Таким
образом мы приходим к важнейшему понятию в
технологии многобайтных символов : Shift
State (можно перевести как Регистр
или Состояние Регистра). На самом
деле, таких состояний (регистров) может быть
несколько, они могут быть
взаимоисключающими, или же действовать
одновременно и независимо.
Отсюда несколько важных выводов : при обработке многобайтовых символов необходимо сохранять текущее состояние Shift State. Длина байтовой последовательности более не соответствует количеству печатных символов в строке. То есть, взяв символ по смещению НАЧАЛО+8 мы не можем достоверно сказать, что это именно 8-й отображаемый символ. Точно также, мы не можем сказать, в каком кодовом наборе необходимо будет отобразить этот символ. То есть, строка имеет историю. И получить полную информацию мы можем только просмотрев строку с начала (считается, что имеется некое "начальное состояние" регистров).
Другая проблема связана со свойством "длина строки". Для строк, состоящих из многобайтовых символов, длина строки "в символах" не равна длине строки "в байтах". Например функция strlen() может работать некорректно. Поэтому, многие системы с поддержкой многобайтовых символов часто имеют две различных функции, например : char_len() и octet_len().
Существует несколько схем организации (кодирования) многобайтовых последовательностей. Самые распространенные :
Менее распространенные : EUC, Shift-JIS (DBCS). С некоторой натяжкой к Multibyte можно отнести UUENCODE, BASE-64 (вместе с QP) и NCR.
Самое большое влияние на Multibyte chars оказал стандарт ISO-2022. Его текст к сожалению доступен только за деньги, но существует его полный бесплатный аналог ECMA-35.
Согласно стандарту ISO-2022 вводится понятия "управляющий символ" и "графический символ", напрмер CR, LF или ESC - это управляющие символы. Соответственно, все пространство из 28=256 символов разбивается на четыре части :
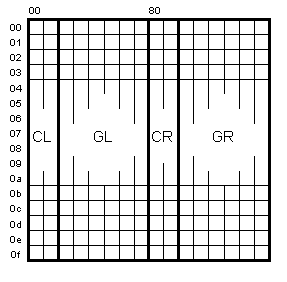
Таким образом под "отображаемые" символы (Graphic) отводится только 256-2*32=192 позиции, 96 GL и 96 GR (иногда 94, без первой и последней позиций).
Одной из функций "управляющих" символов является переключение наборов символов в GR и GL. То есть, вся "пляска" происходит внутри 8-ми битного пространства. Для этого применяется управляющие ESC-последовательности, "старший" ESC - CSI и коды SI и SO. Например, уже упоминавшийся КОИ-7 сделан в точном соответствии со стандартом ISO-2022, путем переключения GL кодами SI и SO (Удивительно ?).
Например, большинство принтеров используют для переключения кодовых наборов именно различные ESC-последовательности. И при вывод на печать постоянно происходит переключение "наборов символов" с помощью управляющих кодов. Точно такая же картина с терминалами. Например терминалы DEC VT-XXX или Wyse имеют множество национальных наборов символов, вшитых в микрокод. Даже код переключения кодовых наборов у консоли Linux (echo -ne "\033(K" ) -- это тоже разновидность последовательности ISO-2022. ( см. man console_codes )
Каждой половине, GR и GL, может быть назначен определенный набор символов (Charset). Существуют четыре набора графических символов G0/G1/G2/G3, каждый из которых может быть подключен на место GL или GR. Как правило, в 8-ми битных системах для GL назначается обычный ASCII, а GR переключают.
Control code 7-bit form 8-bit form Notes
LS0 0x0F 0x0F ^O; also called shift-in, SI
LS1 0x0E 0x0E ^N; also called shift-out, SO
LS2 0x1B6E 0x1B6E ESC n
LS3 0x1B6F 0x1B6F ESC o
SS2 0x1B4E 0x8E ESC N
SS3 0x1B4F 0x8F ESC O
LS1R n/a 0x1B7E ESC ~
LS2R n/a 0x1B7D ESC }
LS3R n/a 0x1B7C ESC |
Вдобавок, каждый из Charset-ов G0/G1/G2/G3 тоже можно сменить с помощью "назначателей" (designators). Получается довольно сложная и громоздкая система. А все из-за 8-ми битного байта !
См. ISO 2375 International Register of Coded Character Sets - описывает различные "назначатели" (designators).
См. ECMA-35 - полный аналог ISO-2022 (бесплатно).
При чтении стандарта ISO-2022 и ECMA-35 может ввести в смущение необычная схема нумерации кодовых позиций, например 2/5. На самом деле, это номер колонки (0..15) и номер символа в колонке (0..15). То есть фактически это шестнадцатеричные числа ! Упомянутое выше число 2/5 означает шестнадцатеричное 0x25 (3710). Символ ESC - это 01/11 == 0x1B == 2710.
Международные стандарты серии ISO-8859-x (например ISO-8859-1 : Latin1) сконструированы с учетом требований ISO-2022 . "Назначатели" для них также стандартизованы. Например для кодировки ISO-8859-5 "назначателями" будут : G1 - ESC 2/13 4/12; G2 - ESC 2/14 4/12; G3 - ESC 2/15 4/12.
Одним из недостатков ISO-2022 является запрет на использование позиций "старших" управляющих символов C1 (0x80-0x9F) для кодирования букв. Например, кодировка CP-866 не соответствует стандарту ISO-2022, поскольку код буквы "Ы" (0x9B) совпадает со старшим ESC (CSI).
Кодировка ISO-2022 является "внутренней" кодировкой для Emacs.
Кодировки на основе ISO-2022 практически в "чистом виде", то есть вместе с ESC-символами и "назначателями" широко применяется для кодирования японских символов (система JIS) и имеют зарегистрированные MIME charset-ы: ISO-2022-JP (RFC-1468) и ISO-2022-JP-1 (RFC-2237).
Система X Window проектировалась в 1970-х годах и в качестве "внутренней" кодировки международных символов в ней была применена схема CTEXT (Compound Text Encoding). Эта кодировка используется вне зависимости от кодировки "целевой" операционной системы (Unix, Windows). Поскольку X - сетевой протокол, то кодировки клиента (множества клиентов) и X-сервера могут различаться.
В кодировке CTEXT могут сохраняться свойств окон X (window propirties) и "ресурсов" внутри X сервера. Эти же "ресурсы" используются для межпрограммного общения через ICСCM и для общения X-программы с WindowManager-ом.
Эта схема кодирования идеологически довольно близка к ISO-2022, но поддержка управляющих символов сильно упрощена и "назначатели" в ней часто применяются другие (хотя для упоминавшейся выше ISO8859-5 -- тот же самый: 4/12 ). Кроме того, схема CTEXT более гибка и позволяет добавлять новые кодировки (например Windows-1251) как "other ecoding" - то есть просто по имени.
Стандарт на кодировку CTEXT свободен и имеется в комплекте документации на систему X (например XFree) или тут.
Для преобразования строк в "свойства" существуют функции XmbTextListToTextProperty() / XwcTextListToTextProperty() и обратные XmbTextPropertyToTextList() / XwcTextPropertyToTextList() где для кодирования в COMPOUND_TEXT может использоваться XCompoundTextStyle.
В результате мы получаем Си-строку, в которой коды символов перемежаются кодами "переключения кодировки". Соответствие между "назначателями" CTEXT и названием кодировки (напр. *-iso8859-1) могут использоваться для выбора шрифта XLFD (X Logical Font Description) для отрисовки данной строки символов в окне, заголовке окна X или подписи под иконкой в Window Manager-е.
Самые последние версии спецификации CTEXT (>1.1) имеют расширение для интеграции с кодировкой UTF-8 (имеют стандартизованный "назначатель" для UTF-8).
UTF-8 применяет совершенно другую схему образования многобайтных кодов.
Изначально символы из набора UNICODE и ISO-10646 закодированы не байтами (8 бит), а 16- или 32-битными числами (wc - wide characters). Для кодирования 32-битного числа ISO10646 применяется следующая схема (RFC-2279)
| U-00000000 - U-0000007F: | 0xxxxxxx |
| U-00000080 - U-000007FF: | 110xxxxx 10xxxxxx |
| U-00000800 - U-0000FFFF: | 1110xxxx 10xxxxxx 10xxxxxx |
| U-00010000 - U-001FFFFF: | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| U-00200000 - U-03FFFFFF: | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| U-04000000 - U-7FFFFFFF: | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
Таки образом, 7-ми битные US-ASCII символы остаются неизменными, а все остальные символы кодируются переменным количеством байт. Максимальное число байт для UTF-8 составляет 6. Символы кириллицы кодируются двумя байтами.
В файле (потоке) UTF-8 никогда не бывает нулевых байтов и управляющих последовательностей (ESC).
Преимущество кодировки UFT-8 в том, что она является само-синхронизирующейся. То есть при потере одного-двух байт, следующий закодированный символ может быть восстановлен. Это выгодно отличает ее от ISO-2022, в которой стоки имеют state (состояние) и при потере "назначателей" (designators) мы теряем сведения о кодировке.
JVM (Java Virtual Machine) использует кодировку UTF-8 в качестве "внутренней" для хранения строк и включает перекодировку при записи строк в поток "наружу", в файлы и потоки целевой ОС.
![]()
Как работать с многобайтными символами ? (API)
В стандарт POSIX включено целое семейство функций для работы с многобайтными символами. mb* в том числе и для преобразования многобайтных символов в "широкие" wc*
http://www.cl.cam.ac.uk/~mgk25/unicode.html